
Возможности катастрофоустойчивого облака
Минимизация простоев при авариях в одном из дата-центров.
Старт виртуальной машины на резервной площадке – от 2 минут.
Синхронная репликация и сохранность данных при переключении на резервную площадку (RPO=0).
Балансировка нагрузки между двумя дата-центрами.
Как это работает
Полное резервирование всех элементов кластера:
- серверы,
- СХД,
- сетевое оборудование,
- оптоволоконные трассы, соединяющие площадки OST и NORD.
Репликация данных на уровне СХД
Информация практически одновременно записывается на локальную и резервную СХД. Recovery Point Objective (RPO) – 0 минут. На одной СХД хранится оригинал данных, на другой – их реплика. В случае аварий вы не теряете данные.
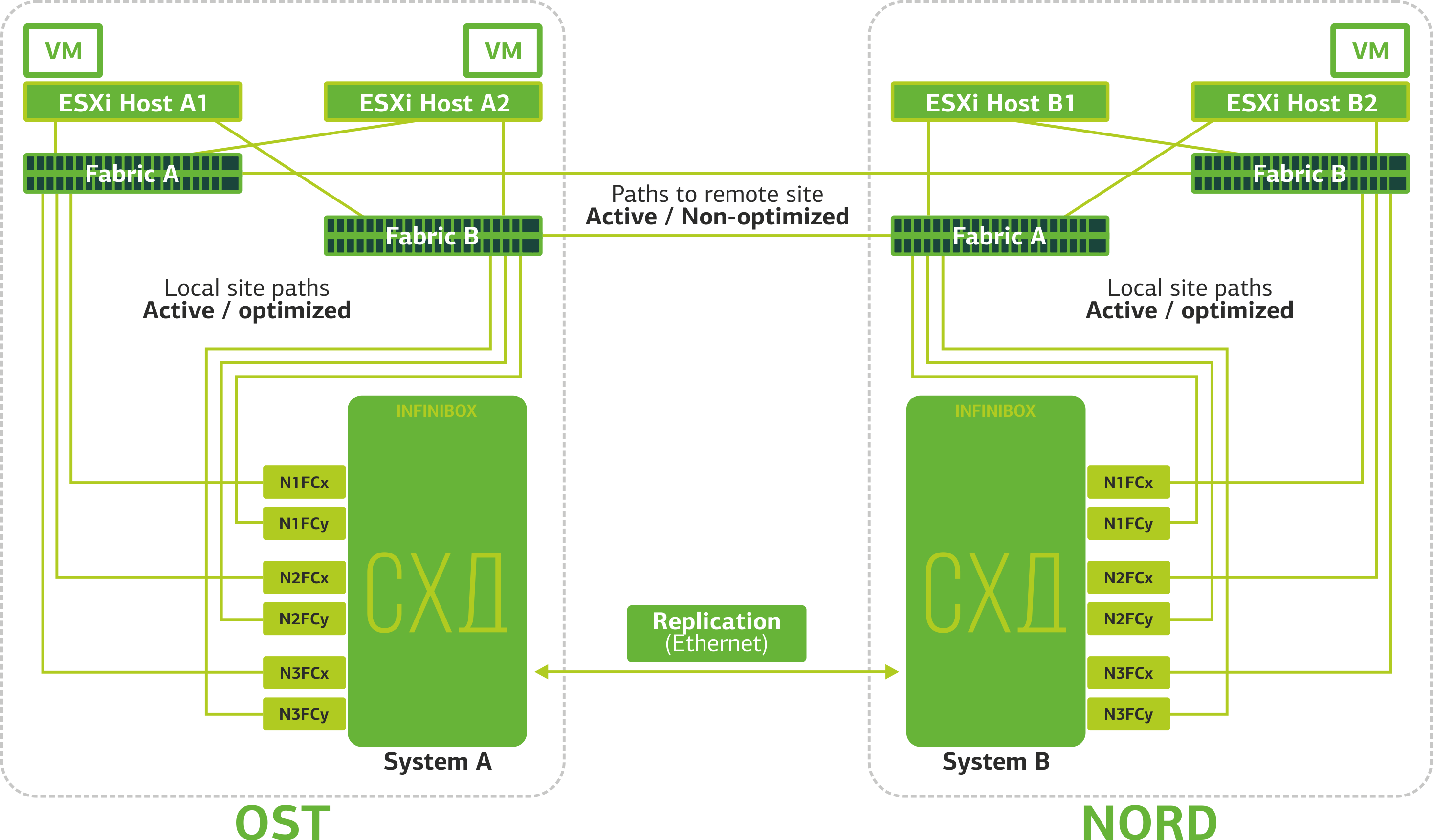
Что происходит с данными и сервисами в случае различных отказов

Виртуальные машины работают штатно.

Виртуальные машины работают штатно.

Виртуальные машины перезапускаются на других серверах – на той же или же удаленной площадке.
Время перезапуска – до 1 минуты.

Все виртуальные машины перезапускаются на резервной площадке через 2,5 минуты.
Виртуальные машины работают штатно.
Виртуальные машины работают штатно.
Виртуальные машины перезапускаются на других серверах – на той же или же удаленной площадке.
Время перезапуска – до 1 минуты.
Все виртуальные машины перезапускаются на резервной площадке через 2,5 минуты.
Финансовые гарантии качества
Для всех клиентов услуги «Катастрофоустойчивое облако» мы предоставляем детальное Соглашение об уровне обслуживания (Service Level Agreement, SLA). Здесь представлены основные параметры и показатели, за соблюдение которых мы несем финансовую ответственность:
99,99% гарантированная доступность сервиса
1000 IOPS / 1 TB SSD/SAS гарантированная производительность дисковой системы
MIPS / 1 vCPU ≥ 1700 скорость процессора
2,5 минуты RTO
Почему мы?

Не нужно содержать свою резервную площадку, покупать и содержать инфраструктуру, лицензии.

Катастрофоустойчивое облако развернуто на базе собственных дата-центров Tier III в Москве.

Финансовая ответственность за нарушение гарантированных параметров сервиса.

Техподдержка 24х7 по почте и телефону.